
【论文阅读】CVPR2019文本图像生成《SDGAN》
基本信息
论文标题:《Semantics Disentangling for Text-to-Image Generation》 —— 用于“文本转换至图像”的语义分解,实现跨模态转换。
**论文链接:**https://arxiv.org/abs/1904.01480v1
研究领域:计算机图形学,Text-to-Image,深度学习(Deep Learning),生成式对抗网络(GAN)
**发表会议:**2019 CVPR
**研究意义:**这篇文章属于Text-to-Image一类,它所解决的主要任务是如何根据文本的描述生成相应的图像,不仅要求生成的图像要清晰真实,而且更要求其符合给定的文本描述。作者提出了一个全新的文本图像生成模型,对输入语句进行语义分离,使其满足高级语义一致性的同时,达到低级语义多样性。
主要贡献
首先预览一下大致的实验效果:

如上图所示,SDGAN和之前的StackGAN、AttenGAN进行了对比,从生成的图像可以直观的看出SDGAN的结果更清晰,同时与描述文本更相符,那么它是做了哪些工作才得到这么好的效果呢?
题目是Semantics Disentangling for Text-to-Image Generation,将其翻译过来为用于用于Text-to-Image的语义分解,从中我们可以知道它是基于文本的语义来改进Text-to-Image的工作,进一步可以猜测它应该是考虑文本的高级语义和低级语义。
作者指出由于对于同一张图像来说,不同的人会给出不同的描述,它们自然包含了对于图像主要信息的描述,同样也充满了多样性和个性化,因此如何从中提取出一致性的语义信息,同时保留描述的多样性和其中的细节信息,成为了Text-to-Image任务的一大难题。
总结来看,本文的主要贡献如下:
- 从文本中提出共享语义:SDGAN从文字描述中提取出公共语义,使得生成的图像可以在表达变体下保持一致性。第一次在跨模态生成中引入Siamese机制。
- 保留文本中的语义多样性和细节。Siamese可能失去独特语义多样性,因此通过语言线索(linguistic cues)重新构造批量标准化层,来设计增强的视觉语义嵌入方法( visual-semantic embedding method)。语言嵌入可以进一步指导细粒度图像生成。
概念介绍
在正式理解SDGAN模型之前,我们需要补充一些相关的基础知识,因为对于文本和图像跨模态这块,我确实啥啥都不会!
高级语义一致性
由于人类对某个事物的文字描述和语言习惯既主观又多样,因此即使是对同一张图像,一百个人可能给出一百种不同的描述。那么这也意味着,在文字图像生成的过程中将会面临一个问题,即如何才能保证两段对同一张图片的描述所生成的图片在整体上看上去是类似的呢?
作者给出了一个例子,在这张图中,a-i是原始图片,a-ii是对这张图片进行的两段不同描述,但大意相同,a-iii是使用现有的GAN网络生成的图片。显然,你会发现尽管它们是从相似的一段文字中转换而来,但这两张生成图像几乎可以认为不是同一种鸟类,也就是差异性非常大。
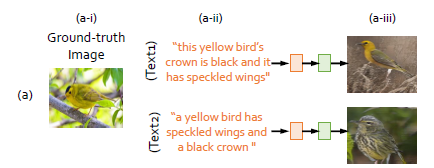
此时得到的结论是,描述文字(description)的变化可能导致图像生成结果的不同。作者认为,至少我们应该保证:如果两段文字描述具有非常相似的语义,那么生成的图像应该在整体上相似。提出来的高级语义一致性,实际上就是为了保证在不同的文字表达下,生成的图片能根据相同或相近的语义而具有一致性(相似性),实现语义共享。考虑了机器学习中类内和类间的概念,相似描述的文字在特征空间中应该距离小,属于类内;而不同描述距离应该大,属于类间。
在本文中提出的Siamese网络,能够提取出两段文字的公共语义,使得该问题得到了很好的解决。
低级语义多样性
和高级语义不同,低级语义比较注重细节和语义的多样性,是在保证高级语义一致性的情况下需要考虑的。既然是两段不同的表述,生成的图片要是完全一样就没有意义了,所以反倒是应该鼓励细粒度的多样性。此时又引入了语义条件批量规范化(Semantic Conditional CBatch Normalization),以保留语义多样性和细节。希望更细粒度的语言嵌入(linguistic embedding)能调整控制生成的图片更多样更精细。
基于以上两点介绍,我们可以先看看引入了Siamese和SCBN的Gan网络,其生成结果会有什么不同?
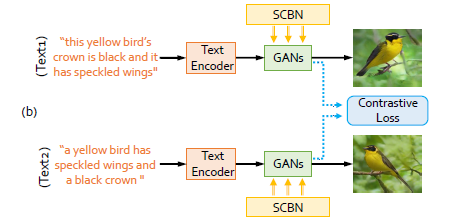
Siamese网络
Siam是古代对于泰国的称呼,可译为暹(xian)罗,Siamese自然可译为暹罗人或泰国人。但Siamese structure network中的Siamese可译为孪生、连体。
Siamese network最早在2005年Yann Lecun提出,它可以看做是一种相似性度量方法,而它所主要解决的是one-shot(few-shot)的任务。one-shot任务是指在现实的场景中,数据集中的样本可能类别数很多,但是每个类别所包含的样本的数量很少,甚至极端情况下只有一张,在这样的情况下,如果使用传统的分类模型去做,往往得到的效果都不会太好,因为传统的模型依赖于大量有标注的样本。而one-shot希望做的就是使用极少的样本也可以得到不错的效果。
Siamese网络(孪生神经网络)可以用来衡量两个输入的相似程度,然后用这个习得的度量去比较和匹配新的未知类别的样本。因为孪生神经网络有两个输入(Input1 and Input2),将两个输入feed进入两个神经网络(Network1 and Network2),这两个神经网络分别将输入映射到新的空间,形成输入在新的空间中的表示。
其模型结构如下图:
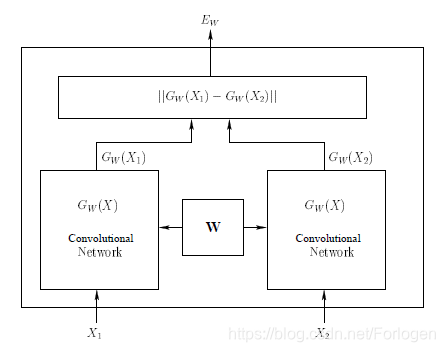
通过Loss的计算,比如说计算两者的欧式距离,来进一步评价两个输入的相似度。相似输入的欧氏距离小,差别较大的两个输入得到的欧式距离较大。
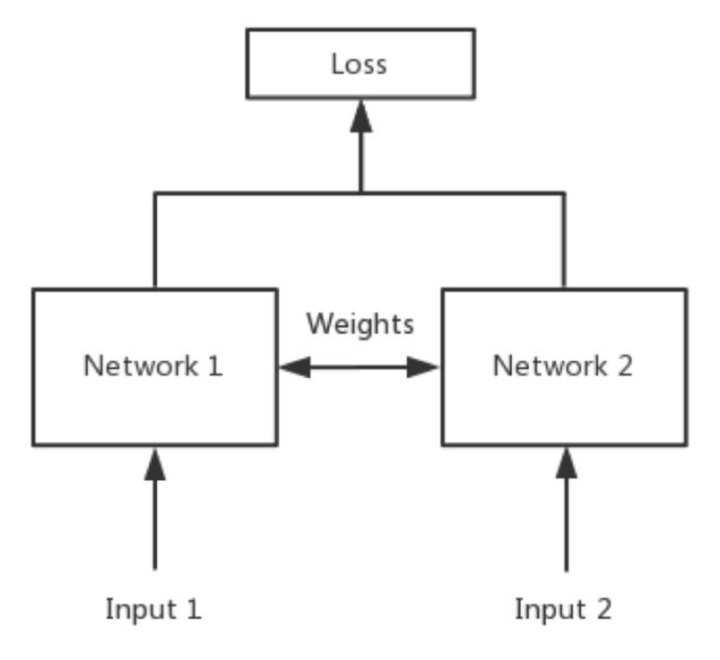
如果只是在pixel空间中进行相似性度量显然不合适,因此Siamese network通过某个映射函数将输入的样本映射到一个目标空间中,然后在目标空间中使用一般的距离度量方式进行相似度比较,希望同类的样本的距离应该相近,而不同类别的样本距离应较远。
详细介绍可以参考博客:
Batch Normalization
BN是优化神经网络训练一个很重要的工具,大家应该都比较熟悉了,这里只给出一个简单的总结。

BN的过程可以表示为
此外对BN的改进有Conditional Batch Norm,可以将其看作是在一般的特征图上的缩放和移位操作的一种特例,它的表示形式如下所示
其中和通过条件线索c学得。
BN的概念被作者引入了生成模型中,但是我在现有的博客中还没有找到一个比较容易理解的介绍,大致意思是希望将LSTM提取出来的句子特征,能够和图片特征相结合。在本文中,将句子向量作为conditional cues。
可以看看知乎的一篇博客:
SDGAN网络结构
通过前面的介绍,我们已经了解到作者提出了一种新的跨模态生成网络,称之为语义解缠生成对抗网络(SDGAN)。该网络主要包括两个部分:Siamese网络 和 SCBN结构。
其中使用Siamese network在判别器(Discriminator)中学习高层次的语义一致性,使用SCBN来发现 Sentence-level 和 Word-level 的细节信息。这样既可以提取出语义的一致性部分,由可以保留描述的多样性和细节部分。
整体结构图如下:

含对比损失的Siamese结构
SDGAN中,使用Siamese结构来提取文本语义信息,用于跨域生成;使用对比损失来计算生成结果之间的差异,如果是对同一张真实图像的两段文字描述,其对比损失应该尽可能小,如果来自不同图像,损失则尽可能大。
本结构有两个分支,且每个分支由三个部分组成:Text-Encoder(编码器)、Contrastive Loss(对比损失)、Hierarchical generative adversarial subnets(分层生成对抗网络)。
TextEncoder
每个分支的输入都是一句话,文本编码器E的目标就是从自然语言介绍中学习到特征表示( feature representations),采用双向长短期记忆(Bi-LSTM)从文本中提取出语义向量。
双向LSTM能够同时利用过去时刻和未来时刻的信息,因此得到的语义向量将更加有意义。通常,在双向LSTM中,隐藏状态用于表示句子中单词的语义,而最后隐藏状态被用作全局句子向量。即表示单词的特征向量和表示句子特征向量。
Hierarchical generative adversarial subnets
本阶段的目标是:使用分阶段的图片生成,完成从低分辨率到高分辨率的转变。其细分成了三个生成阶段,姑且用阶段1和阶段2、3来代替。
给定来自于Encoder的句子特征和从标准正态分布中采样得到的噪声,在阶段1生成低分辨率的图像(64 * 64),生成器为。阶段2 、3 则使用上一个阶段的生成结果,与相结合,生成具有更高分辨率的图像。
一系列的鉴别器则用来区分图像是真的还是假的,这些鉴别器是相互独立的,不需要共享参数。
两个阶段的具体结构如下,左侧是阶段1,右侧是阶段2,用于阶段1,另外两个用于阶段2和3,x为上一个阶段的特征结果。
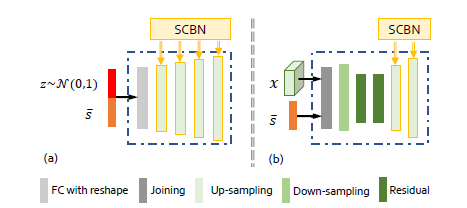
其中的adversarial discriminators是用于判断每阶段生成图像是否符合文本描述的。
Contrastive Loss
先假设上述每个分支在当前阶段结束后,都将得到相应的视觉特征向量和,它们之间的欧式距离记为 $$ d = ||v_1 - v_2 ||*2 $$ 那么此时的对比损失可以记为
- : 当两个分支的文字是对同一张图片的描述时,,反之
- : 特征向量的长度,值为256
- : 平衡参数,当时,其值为1
从公式上可以看出,目标应该是最小化
由于加入了噪声,使得尽管输入相同,输出的向量也不会完全相同。但为了防止生成的图片太过相近,作者修改了一下损失函数:
α 是避免两个描述同一张ground truth的文本生成的图片太接近时取的超参数,一般为0.1。
语义条件批量标准化
CBN与SCBN
利用自然语言描述中的语言线索(linguistic cues)来调节条件批处理归一化,主要目的是增强生成网络特征图的视觉语义嵌入。它使语言嵌入能够通过上下缩放、否定或关闭等方式操纵视觉特征图,SCBN可以从输入中获取到语句级和词级两个层次上的语言线索。如下所示
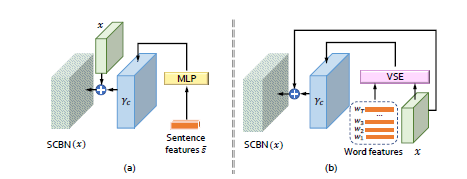
公式为:
是条件线索,在SCBN中,该线索由两部分组成,句子层级的线索(sentence-level cues)和单词层级的线索(word-level cues)。本阶段的重点是得到。
其实这个部分基本没看懂,代码还没公开,所以接下来靠盲猜完成,可能猜着猜着就懂了。
Sentence-level Cues
在保证一致性方面,考虑全局向量作为线索,并使用包含一层隐藏层的MLP来得到,将得到的结果拓展成与的维度相同,以此嵌入语言提示和视觉特征。接着得到的结果再feed入下一个SCBN。
Word-level Cues
是单词特征的集合,表示第t个单词的特征向量。可视化语义特征向量(visual-semantic embedding (VSE))模型是为了融合单词特征和可视化的特征提出来的.
正如上图所示,我们用一个感知层(如)去将文本的特征和可视化的特征匹配起来。是在嵌入特征向量 的基础上来计算算每张图片的第 j 个区域,而 是 的动态表示。
表明可视化特征层第j个子区域的第t个单词向量的第t个权重。σ(·)是softmax函数。
实验设置
数据集
数据集为CUB 和 MS-COCO。
- CUB:包含200种鸟类,包括11788张图像,每张图像都有10种描述。其中8855张作为训练集,2933张作为测试集。
- MS-COCO:80k训练集和40k验证集,每张图像都有5种描述。
训练细节
除了第二节中引入的对比损失,其所提出的SD-GAN的生成器和鉴别器损耗遵循AttGAN中的训练过程,详细参考博客:论文阅读:AttnGAN,一种attention-driven的多级的细粒度文本到图像生成器。
模型评估
包括了预先训练的Inception模型评估,作者还另外设计了主题测试来评估模型性能。
作者为CUB测试集中的每个类随机选择50个文本描述,在MS-COCO测试集中随机选择5000个文本描述。给出相同的描述,要求50个用户(不包括任何作者)通过不同方法对结果进行排名,计算人类用户排名最佳的平均比率以评估比较方法。
实验结果
暂时不对所有的实验结果逐一介绍了,选取其中比较重要且明显的对比做解释。
通过在CUB和MS-COCO两个数据集上进行实验,证明了SDGAN优于已有的模型

进一步通过实验证明了Siamese mechanism和SCBN的有效性

最后显示了SDGAN可以对描述文本中小的变化做出相应的改变:

总结
整体来看,本文所使用的模型架构和新提出的SCBN具有一定的吸引力,为后面Text-to-Image 任务的解决提供了新的思路。





