【论文阅读】《Style2paints》
在读论文的时候发现了这篇文章,写得非常好,所以想做个搬运。
基本信息
1. 论文标题:《Style Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GAN》 —— 基于改进的残差型U-net和带辅助分类器的GAN(AC-GAN),实现动漫线稿的迁移式(自动)上色。
2. 论文链接:https://arxiv.org/abs/1706.03319
3. 研究领域:计算机图形学,线稿自动上色(Sketch Colorization),风格迁移(Style Transfer),深度学习(Deep Learning),生成式对抗网络(GAN)
4. 作者:Soochow University: Lvmin Zhang, Yi Ji, Xin Lin, Chunping Liu
5. 发表会议:2017 4th IAPR Asian Conference on Pattern Recognition (ACPR)
6. 关键词:动漫线稿自动上色算法,Style2paints算法原理,Style Transfer for Anime Sketches with Enhanced Residual U-net and Auxiliary Classifier GAN论文解读,基于风格迁移的线稿上色算法。
7. 代码与模型:
-
官方代码:Style2paints(PaintsTransfer)的GitHub仓库(仓库Star数量已超过一万)。提供了完整的上色程序与训练好的模型,暂未提供训练代码。论文对应Style2paints V1,GitHub代码版本持续更新。
-
非官方复现:(未测试,仅供参考)SerialLain3170/Colorization – “Experiment with reference”部分。使用了替代的网络结构,包含训练代码。
8. 研究意义:
- 在动漫线稿迁移式(自动)上色领域,本文是第一篇实现较好上色效果的论文(曾提供了在线上色网站),开源了代码和模型。
- 本文的改进版本"Two-stage Sketch Colorization"(论文解读)发表在ACM Transactions on Graphics (SIGGRAPH Asia 2018 issue),使用了类似于本文的网络结构。
主要贡献
1. 主要贡献:
-
设计了一个能够对动漫线稿进行迁移式上色的网络
-
对U-net进行了改进,设计了残差型U-net (Residual U-net)
-
设计了一种带有两个辅助损失函数的U-net训练方式
-
对AC-GAN的判别器进行了修改,使之适合于判别图像的上色风格类别。
2. 核心参考文献:
两篇黑白照片彩色化论文:
- 《Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification》ACM Transactions on Graphics (Proc. of SIGGRAPH 2016), 35(4), 2016.
- 《Real-time user-guided image colorization with learned deep priors》ACM Transactions on Graphics (TOG), 9(4), 2017.
数据集
作者在Github项目主页上说明,推荐的训练集为nico-opendata,数据集大小为四十万张彩色漫画。
由于缺少原始线稿图像,对应的线稿,使用sketchKeras从彩色漫画中自动提取。
问题定义
给定一幅黑白线稿A(未上色),和一幅已上色的彩色漫画B(与线稿A无关),能否根据彩图B的上色风格,自动对线稿A进行上色?
即:将B的上色风格(语义信息)迁移到A上。该问题称为:动漫线稿的迁移式上色(Style Transfer for Anime Sketches),也称为基于范例的上色(Exemplar-based Colorization)。
其优点在于:能够实现全自动上色,无需人工干预(在上色效果较好的情况下)。

问题定义:动漫线稿的迁移式(自动)上色
- 动漫线稿上色与“黑白照片彩色化”(Photograph Colorization)的区别:黑白照片除了提供边缘信息之外,还提供了各像素的灰度值、纹理等信息,而线稿只提供了边缘信息,所以线稿上色的难度要大得多。
-
与“语义分割”(Semantic Segmentation)问题的区别:(a)训练数据中不包含每个像素的分类标注信息,(b)智能上色的过程,不是简单地对身体的各部位进行语义分割,还需要添加自然的颜色过渡、纹理等。

相关工作
-
PaintsChainer:在本文写作时,PaintsChainer发布了V1版本(GitHub仓库)。Paintschainer V1仅提供了全自动上色和基于颜色提示(Color Hint)的线稿上色,未提供基于风格迁移的线稿上色功能。
-
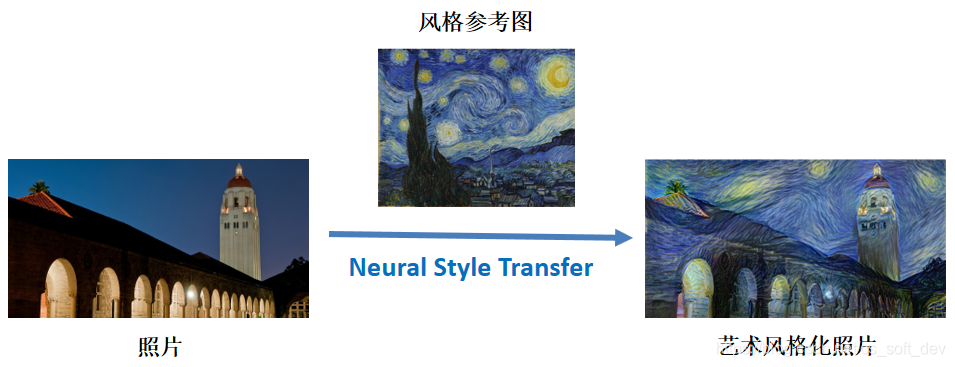
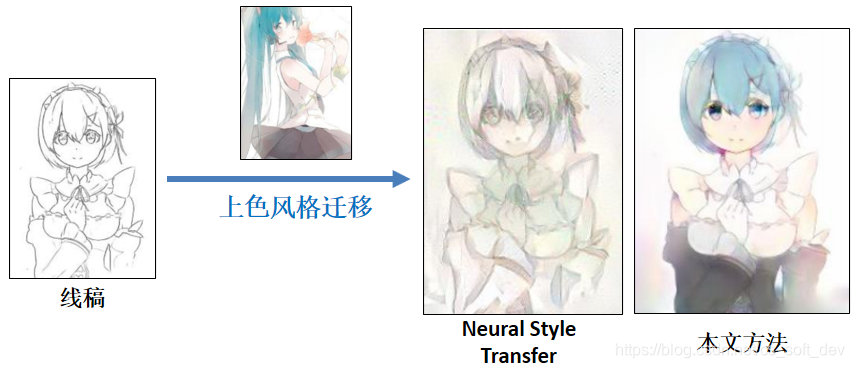
Neural Style Transfer(神经风格迁移):虽然Neural Style Transfer是最常用的图像风格迁移方法,但本文的实验结果表明,Neural Style Transfer不适合用于“动漫线稿的迁移式上色”问题,实验结果如下图所示。参考文献:[3] L. A. Gatys, A. S. Ecker, and M. Bethge. A Neural Algorithm of Artistic Style. ArXiv e-prints, August 2015
整体网络结构
本文网络的整体网络结构设计如下:
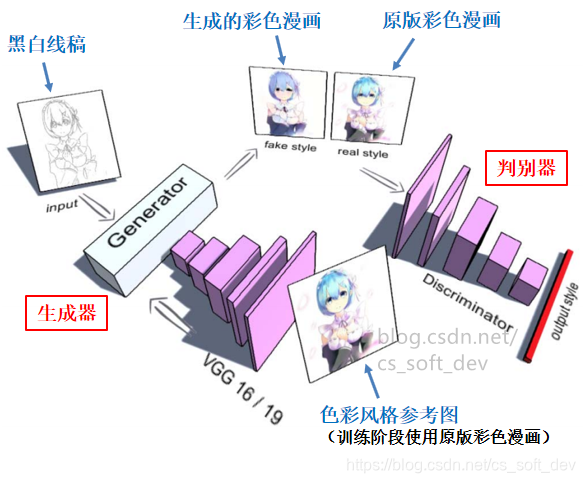
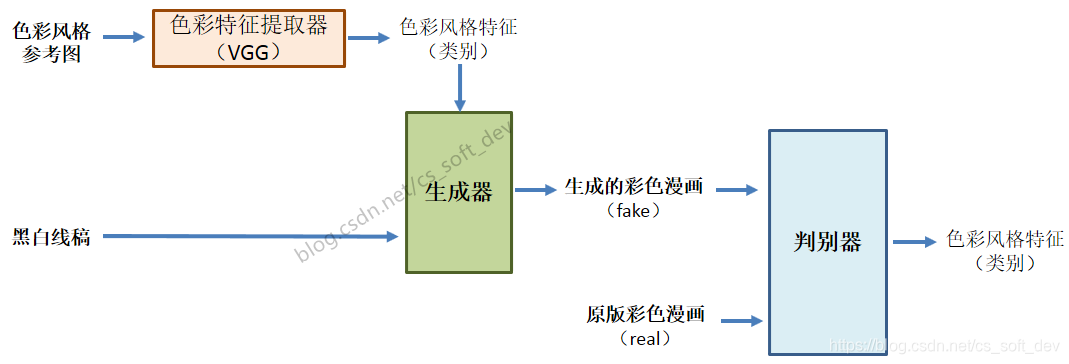
Generator生成器
Generator网络结构
-
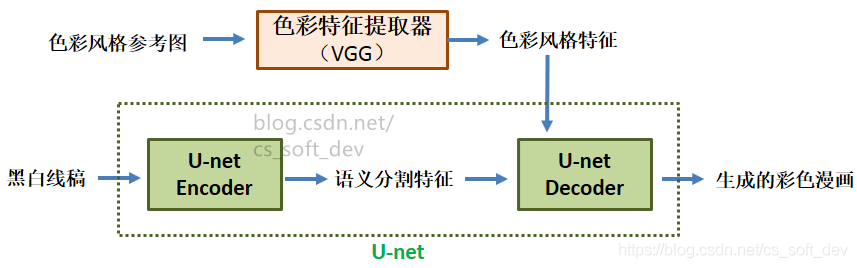
使用VGG16/19从“色彩风格参考图”中提取“色彩风格特征”,然后将其输入到U-net的中层。色彩风格特征包含了上、下身衣服颜色,头发颜色,背景颜色等信息。(色彩风格特征向量也可视为色彩风格类别的分类结果)。
-
使用U-net完成从“黑白线稿”到“已上色漫画”的转换。U-net分为Encoder和Decoder,Encoder提取出的“语义分割特征”与VGG提取出的“色彩风格特征”,一起传入Decoder。
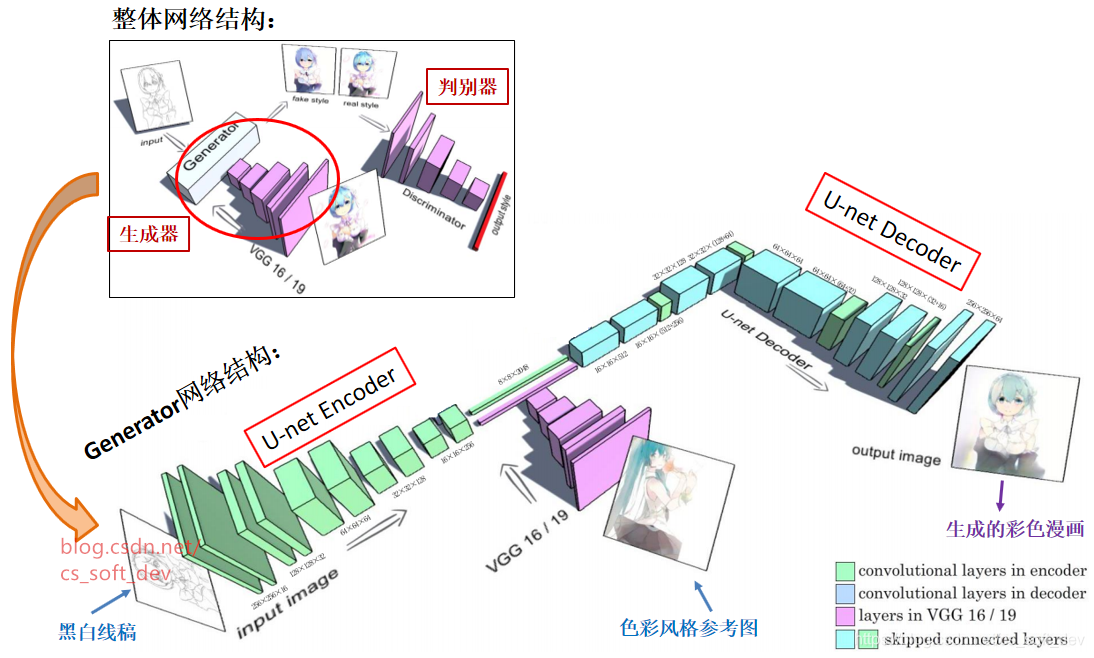
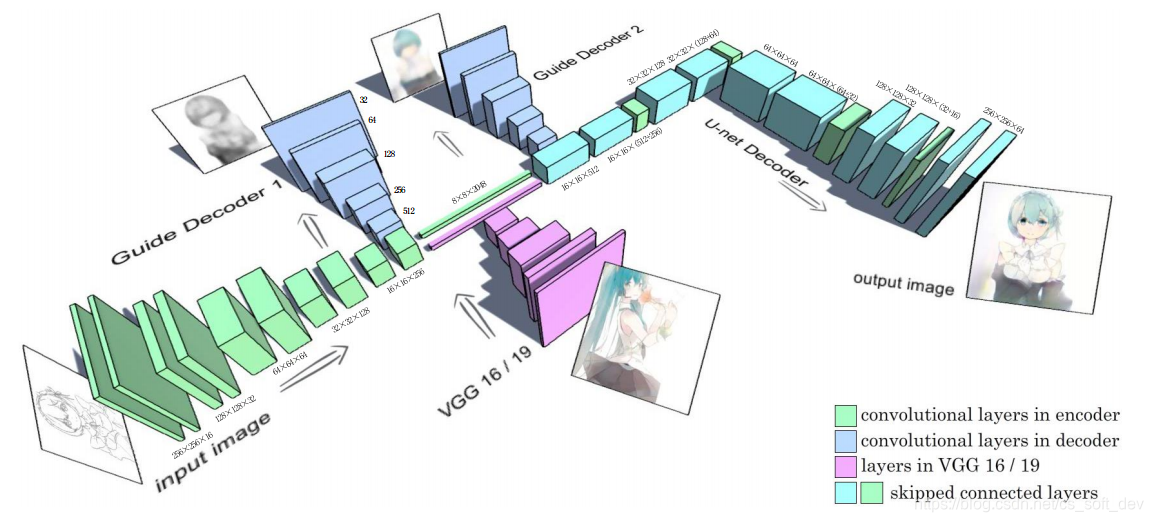
- 为了解决训练时U-net中层梯度消失的问题,训练时在U-net中层的“入口”和“出口”处各加上一个Guide Decoder。其中,入口处Decoder的参考图像为灰度漫画,出口处Decoder的参考图像为彩色漫画。加上Guide Decoder之后的网络结构如下图所示。下图为最终版,添加了2个Guide Decoder。
- 分析:
- U-net是全卷积神经网络(Fully Convolutional Network, FCN)的一种变体,最初用于生物医学图像的语义分割。U-net专为小规模数据集而特别优化设计。使用U-net来完成线稿上色任务,是将**“线稿上色问题”建模为近似于“语义分割问题”**(虽然二者不等价),为图中的每个像素分配一种颜色(类别)。
- VGG的网络权重:在GAN训练过程中,为避免受到干扰,VGG网络的权重的是固定的(VGG网络使用在ImageNet数据集上预训练好的权重)。
Generator损失函数
- 初始的损失函数:
其中,x为线稿,y为对应的已上色漫画。V(x)为VGG19的输出, 为U-net生成的已上色漫画。 和分别是两个Guide Decoder。推荐的参数设置为=0.3,=0.9。
⚠️注意:在训练阶段,输入的“色彩风格参考图”使用的是输入线稿对应的“已上色漫画”。
-
由此引发一个关键问题:训练期间,网络的输入和输出均为同样的“已上色漫画”。那么训练完成后,网络是否会退化为直接从输入向输出拷贝图像?
答:若VGG的权重在训练期间非固定,则网络很可能会退化为从输入向输出拷贝图像。而论文指出,VGG****的权重在训练期间是固定的,所以训练期间VGG提取出的色彩风格特征也是固定的(在训练期间保持不变),所以网络不会被训练成从“色彩风格参考图” 直接拷贝图像到网络的输出。**网络根据“线稿”和VGG提取出的固定“色彩风格特征”,重构出线稿对应的“彩色漫画”。**当训练数据集足够大时,这种训练方式能让网络学到风格迁移的能力。
-
最终的损失函数:
其中T(y)函数用于将彩色图像y转换为灰度图像。由于本文发现将Guide Decoder 1对应的训练图像转为灰度,能够改善上色效果。因此,最终的损失函数如下:
论文没有说明将Guide Decoder 1的参考图设为灰度的原因。猜测可能是因为Decoder 1位于输入色彩风格特征之前,将参考图设为灰度,以避免VGG传入的颜色特征失效。
Discriminator判别器
Discriminator网络结构
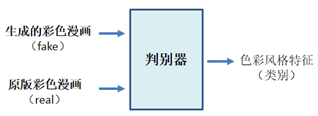
判别器的网络结构,是在AC-GAN (Auxiliary Classifier GAN) 判别器的基础上进行修改。与AC-GAN判别器的区别之处在于:本文的判别器输出不含real/fake二分类,只包含生成图像的类标签。具体而言,判别器的输出为一个4096维的特征向量,与VGG输出特征向量的意义基本相同,可视为色彩风格类别的分类结果。当判别器的输入图像为fake时,输出向量接近于全为0;当判别器的输入图像为real时,输出向量接近于VGG19的fc1层输出的特征向量。
Discriminator损失函数
- 基于对数释然距离(log-likehood distance)的损失函数:
- 公式解释:
-
第一项 为对真实样本的判别,第二项 为对生成样本的判别。希望D(y)越接近norm(V(y))的值越好, 越接近0越好。
-
式(3)中的norm(x)是一个归一化函数,用于对VGG的输出进行归一化,使之更适合于公式中的对数释然距离。推荐的归一化函数如式(4) (5) (6)所示:
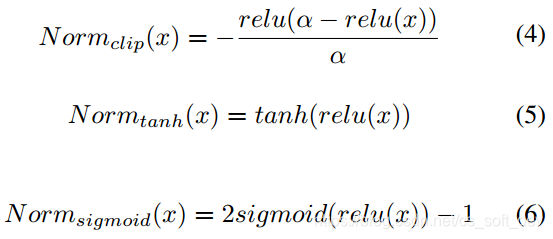
另外,作者还介绍了基于least-squared distance的损失函数,和DCGAN判别器的损失函数(详见论文)。为了取得最佳的上色效果,作者建议结合使用多种判别器和损失函数。
-
作者指出,使用GAN的对抗式训练方法,会造成损失函数值不稳定。因此,训练生成器时,主要使用式(2)的损失进行训练(注意该损失函数中没有出现判别器),而判别器提供的梯度仅作为辅助。
-
最终,GAN的整体损失函数(生成器+判别器)如下:
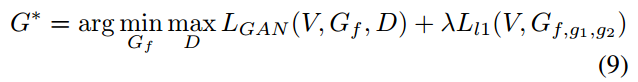
其中:lamda的推荐取值为0.01。
上色效果
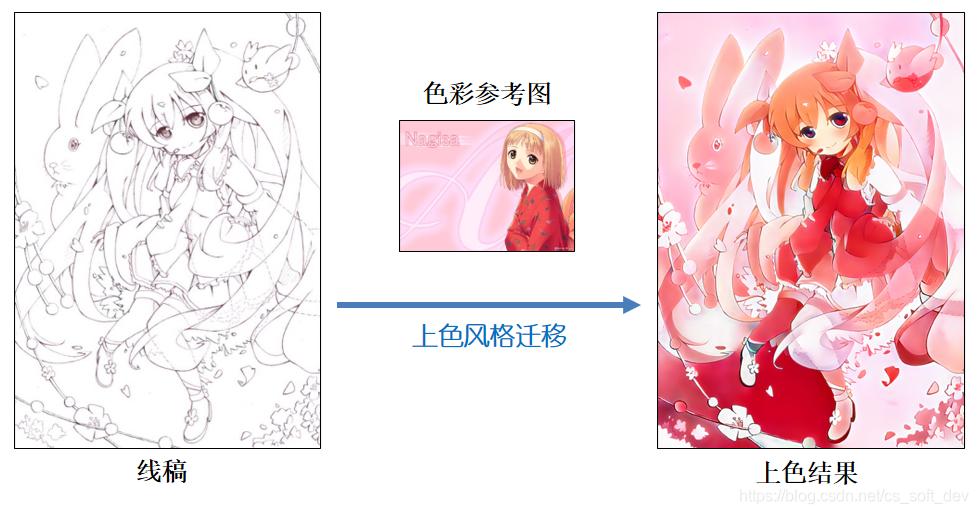
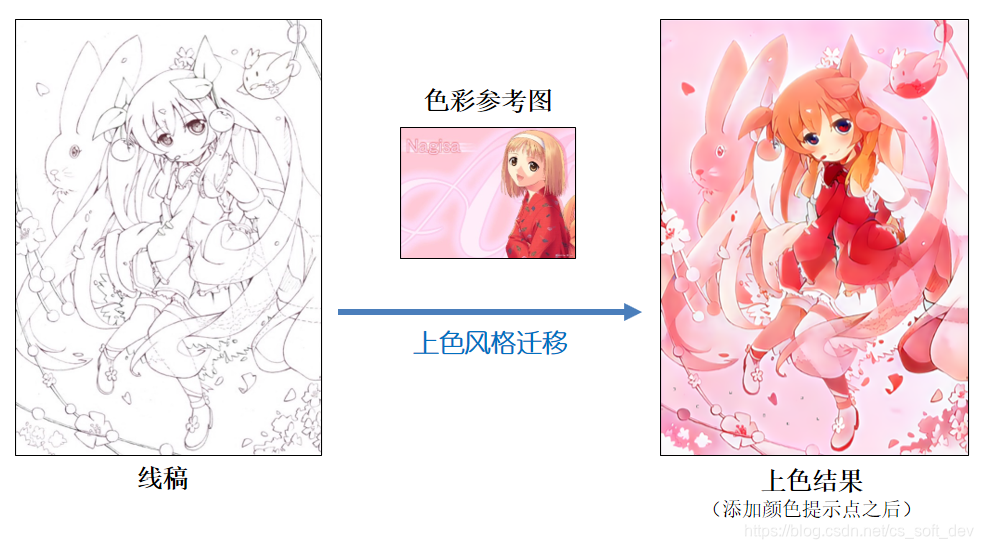
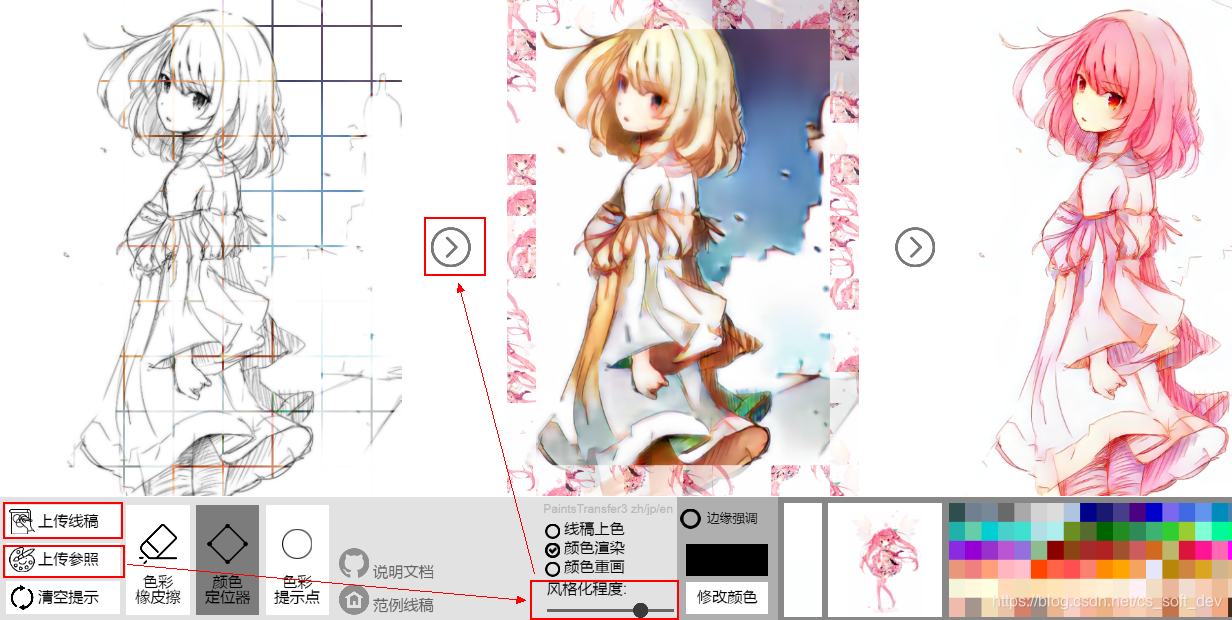
如下图所示,网络能自动区分出线稿和色彩参考图中的头发、眼睛、皮肤、衣服区域,并能将色彩参考图的颜色迁移到线稿上的对应区域。




Style2paints V3/V4.5风格迁移上色效果
Style2paints V3迁移效果
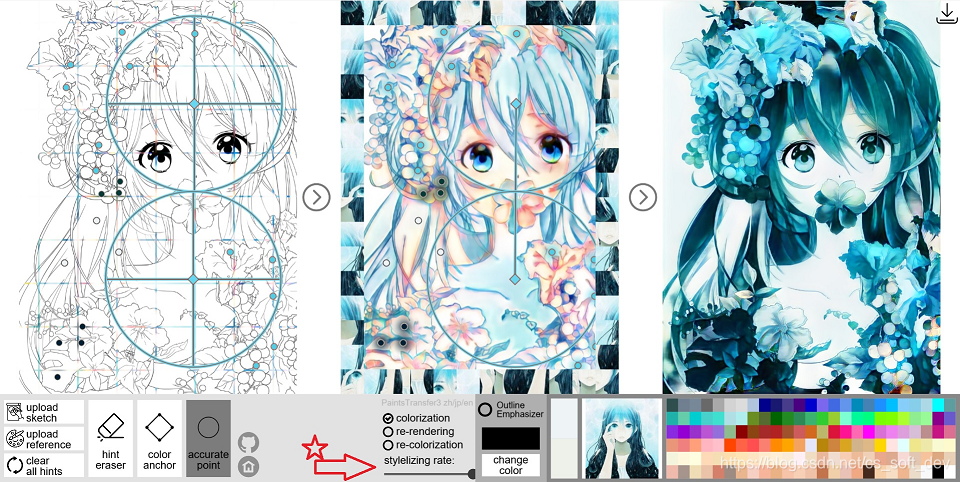
Style2paints V4.5 迁移效果