
【论文阅读】《基于对抗一致性的非匹配图像转换》
前言
在CycleGAN中,它最大的问题在于它要求从目标域转换回来的图像要包含原图的所有信息,而这对于很多任务是不现实的。
比如让我们替一张照片中的人添加一副眼镜,显然眼镜类型是多种多样的,因此最终的添加结果也可能是多种多样的,对于生成器也是如此。再比如性别转换时胡须、头发的变化等等,这类问题都具有不可逆的特性。
因此,当使用CycleGAN为图片中的人摘除眼镜的时候,循环一致性损失(Cycle Consistency Loss)尝试解决此问题时,就必须“作弊”在图片中留下痕迹或减小变化,使得转换回去的图片包含原图的信息,但这也就导致了结果的不真实。
如下图所示,使用CycleGAN处理的图片,眼睛周围的颜色有明显不同或者是眉毛处仍有眼镜的痕迹。

因此,根据这一缺点,作者提出了反向一致性损失(Adversarial Consistency Loss,ACL),目标是使目标域和源域共享的信息最大化,而不是严格保持一致。所以,一致性的丢失可以促使生成的图像从分布的角度包含更多源图像的特征。也就是说,被翻译回来的图像只需要与输入源图像相似,而不需要与特定的源图像相同。
因此,我们的生成器不需要保存源图像中的所有信息,这就避免了在翻译后的图像中留下“作弊”信息。然后作者将对抗性一致性损失、经典对抗性损失和一些附加损失相结合,实现了非配对图像-图像翻译的目标。
该方法在三类非配对图像转换上效果显著,分别是:眼镜摘除、性别转换和动漫人物转换。
论文题目《Unpaired Image-to-Image Translation using Adversarial Consistency Loss》
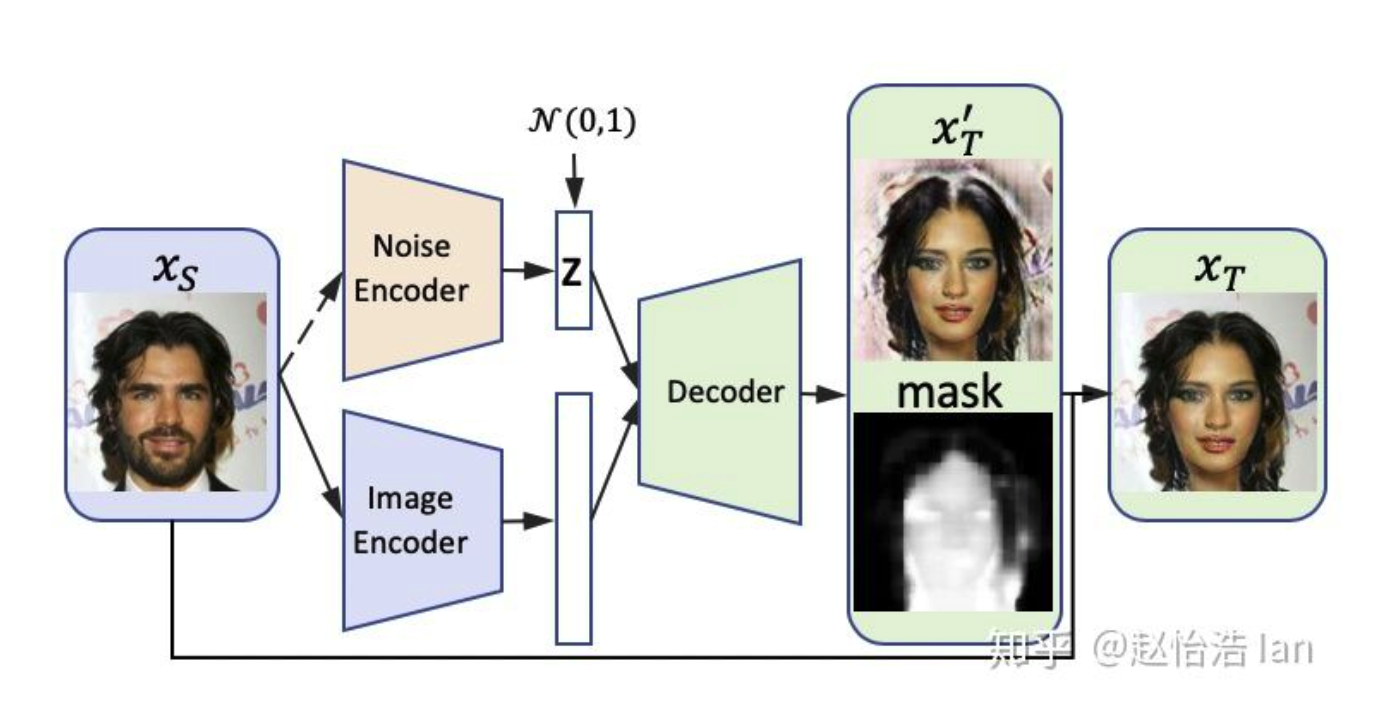
模型框架
本文提出的模型框架如下图所示。本模型包括了两个生成器和三个判别器,为了方便,我们同样使用来表示源数据领域的图像数据,表示目标数据领域的图像数据。
其中,第一组生成对抗网络是生成器(从S到T的生成)和判别器,用于判断图像是否属于领域T;第二组生成对抗网络是反向的生成器(从T到S的生成)和判别器,用于判断图像是否属于领域S。同时还增加了一致性判别器,用于判断图像是属于原图邻域还是还原图片分布的区域,进而拉近两者之间距离。
为了允许不同细节的图片都被认为和原图相同,我们将CycleGAN中的原图,目标图片和还原图片都扩充成分布(加入噪声),那么在眼镜摘除任务中,允许原图和还原后的图片拥有眼镜款式的多样性,那么生成器就不用刻意在图像中保留“线索”,从而得到更高质量的图片。
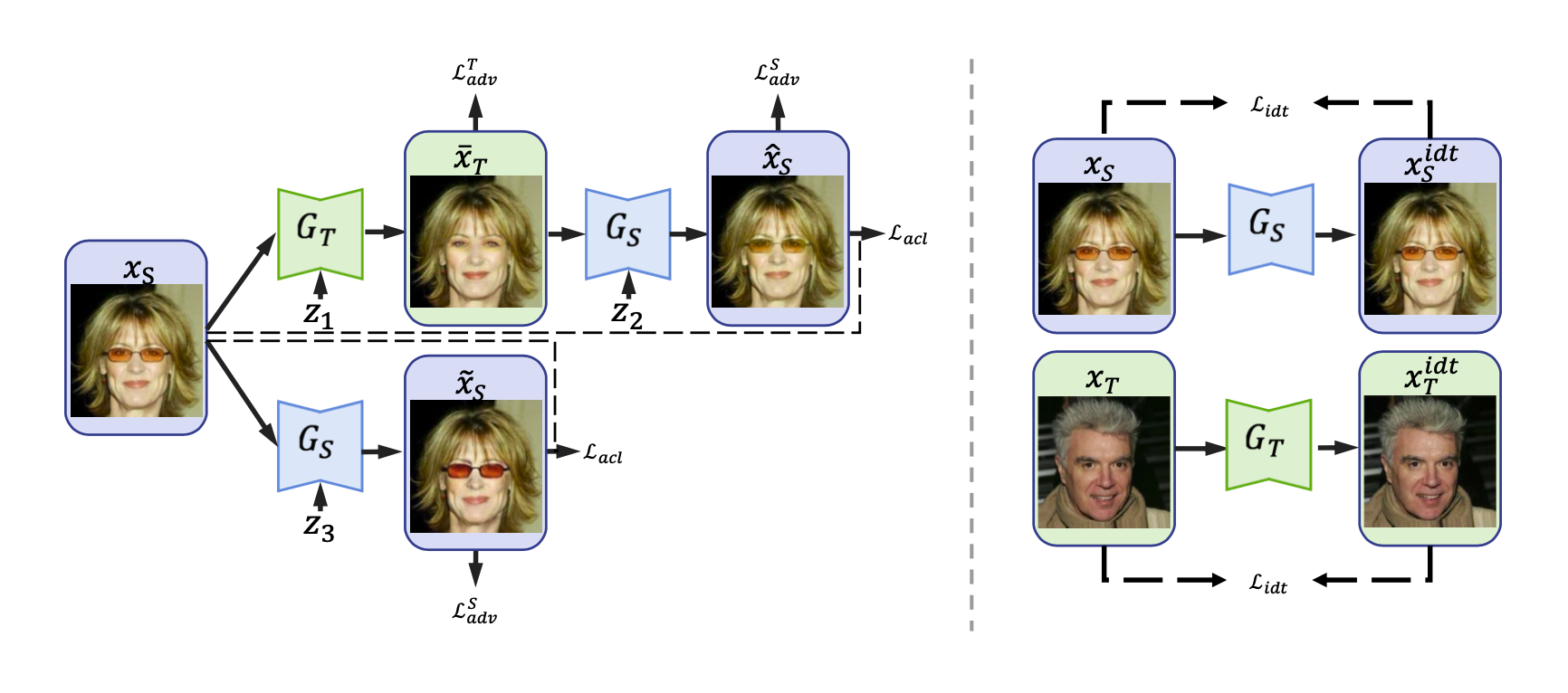
那么,ACL-GAN提出的三类损失函数相结合,使得转换效果得到了明显的改善,它们分别是:
- 反向平移损失(Adversarial Translation Loss):促进生成图像的分布与目标域中的数据分布进行匹配。
- 反向一致性损失(Adversarial Consistency Loss):保证在还原后图像中仍然保留原图像的主要特征。
- 自身损失(Identity Loss)和边界注意掩模(bounded focus mask):提高图片质量,保证人物背景。
损失函数介绍
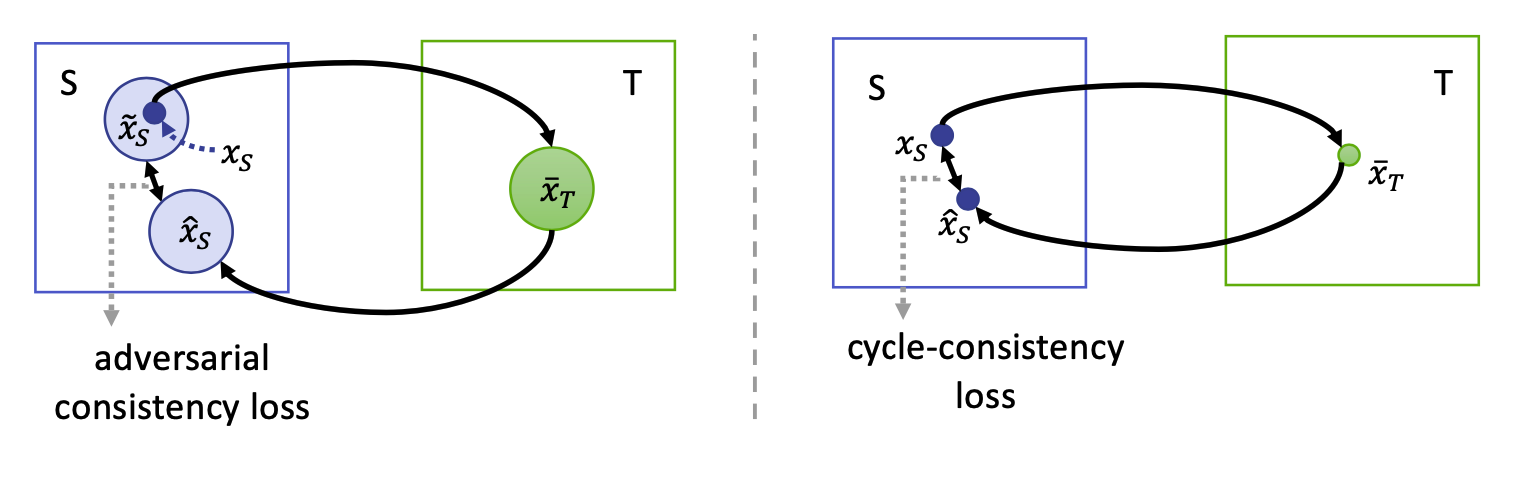
前面我们说到,CycleGAN中严格的像素级别的一致,使得它不能执行几何变化,删除大的对象,或忽略无关的纹理。那么,论文中提出了新思路,并将其与CycleGAN做了对比。
从图中可以看出,在原模型中,我们希望和两点尽可能得接近,但在左侧新模型中,我们将原图,目标图片和还原图片都扩充成分布,其中区域包含了点。
这样做的具体好处是什么呢?我们结合眼镜摘除任务来具体举例:
假设给定一张特定戴了眼镜的特定人像,我们加入一定的噪声,并借助生成器进行眼镜摘除。由于噪声的关系,摘除结果图片将成为一个由无数点组成的分布区域,因此对它还原后的图片加入噪声后也将成为一个分布区域。在中,在开始时,还原图片可能是一些没有嘴没有头发等等的图片,图中的人也可能带上了一些三角形等款式各样的眼镜。
另外,我们对原图再加入噪声,生成一片包含了原图数据的区域。在这片区域中,将包括不同款式的眼镜(因为是眼镜摘除任务,所以主要是针对眼镜),保证了多样性,可能是颜色相同形状不同等等。
然后作者提出最小化两分布之间的距离,将避免在目标图片中留下“作弊”信息。例如现有还原后的图像,我们只需要尽可能地减小它与区域,笔者想把它与原点之间的距离称为弹性距离,该距离允许还原图像与原图之间的不一致性,使得生成器在摘除眼镜的时候更加自由,大胆的把眼镜完全去掉,从而得到更高质量的转换结果。这么做并不会降低准确率,因为生成器将更加注重保留原图的其它特征。
Adversarial Translation Loss
首先,对于第一组生成对抗网络,其处理过程如下图所示,其中表示原图加入噪声后的结果图片,判别器的任务是判别图片是否来自于领域。当图片属于时,将被标记为正样本,反之为负样本。
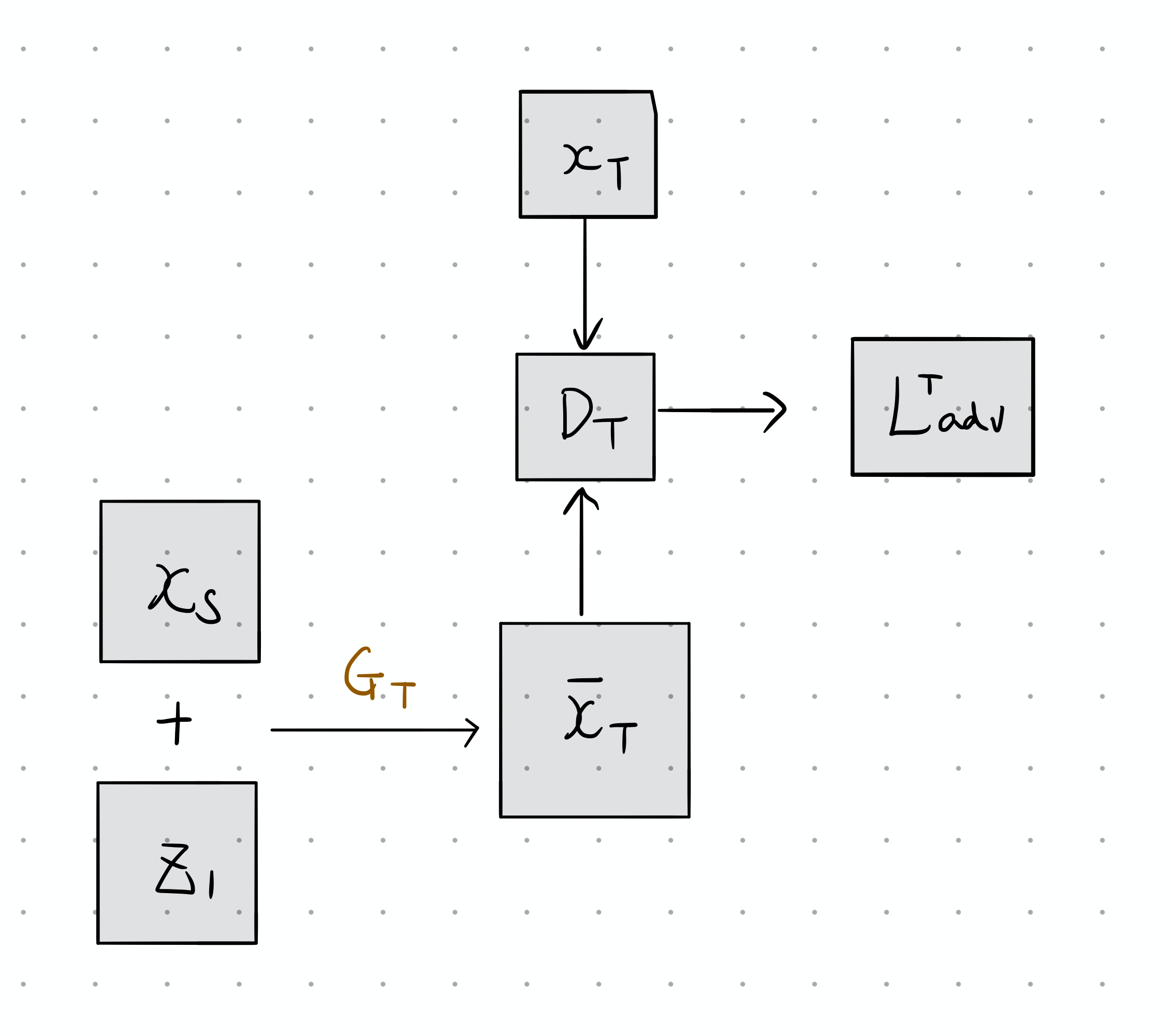
也就是说,在训练判别器时,对于样本点而言,如果它来自,则判别器给出的分数应该越高越好,故也会越来越大,而如果它来自,判别器给出的分数应该越低越好,故会越来越小,为了统一,将越来越大。对于极大极小值问题的解决与GAN是一样的,即
因此,对于此判别器,可以分析其目标函数为:
再看第二组生成对抗网络,其处理过程如下图所示,其中判别器的任务是希望能够区分真实图片和由生成的图片。当图片属于时,将被标记为正样本,其余均为负样本。
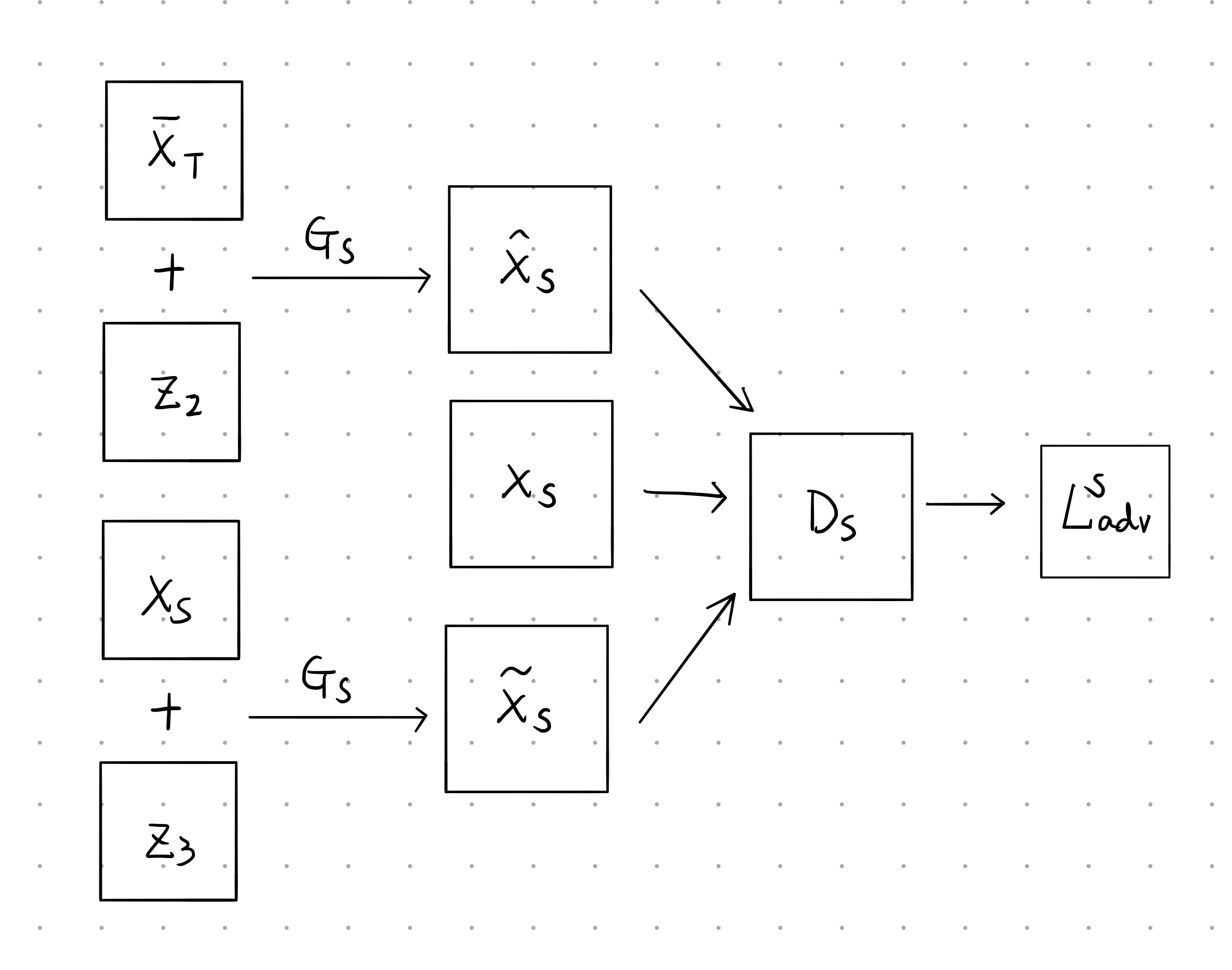
所以在训练判别器时,对于样本点而言,如果它来自,则判别器给出的分数应该越高越好,故也会越来越大。而如果它是由生成的图片,那判别器给出的分数应该越低越好,此时负样本来源有两个,且是有同一个生成器生成的,因此损失值相加之后要除以2。最后优化目标为
这样我们就可以得到反向平移损失:
Adversarial Consistency Loss
接下来就是本文最重要的损失——反向一致性损失。从CycleGAN中我们知道,尽管从直觉上来看,通过两组生成对抗网络独立的训练就能达到我们的目标,但是仔细思考会发现其实是不足够的。
如果我们仅拿其中一组举例,如果生成器希望判别器认为从中转化过来的图片是属于的最好方法是什么呢?它可以不用提取任何有关的信息,直接从中生成数据并作为输出。因此说独立的训练会导致失去各自条件的意义。这也是原文中提到的,损失值的变化仅能够保证在正确的区域内,但是却不能保证它与原图具有相似的特征。例如,将男性的图片转换为女性时,这名女性的面部特征可能会变得跟这名男性的不同(比如发色、肤色等)。
所以作者又提出了使用一致性鉴别器来最小化和之间的距离,此前的循环一致性损失不足以满足我们的需求。我们强调的是尽可能地保留原图的特征,并允许图像多模态的输出,因此并不需要如CycleGAN中那样使用范式,最小化其值来拉近还原图像和原图之间的距离,事实上我们只需要拉近和两个分布之间的距离就可以了,而两者都是使用转换而来的,故用联合分布和来表示。
例如在眼镜摘除任务中,我们将允许还原图像拥有与原图不同的眼镜。因为这样的弹性距离,使得不需要保留任何关于该眼镜的痕迹依次来增大,同时也能保持在一个比较小的状态。
注意,我们现在的目标是最小化两者距离:
也就是说,当输入图像来自的时候,判别器给出的分数应该越小越好,因此$[log( \hat{D}(x_S, \hat{x}_S))] \tilde{x}_S[log(1- \tilde{D}(x_S, \tilde{x}_S))]$越小越好即可,最后另两者相加。
Identity Loss
对于原图或转换后图片加上噪声后产生的图像,可以采用计算自身损失值来保证在图像转换过程中的特征保存,提高翻译图像的质量,稳定训练过程,避免模式崩溃。
为什么这么说呢,还是那眼睛摘除任务举例,我们前面提到了实验过程中最小化和之间的距离,那么这个实际上是有范围的,在这个范围内,允许与原图有部分的不同,但是总不能差异太大吧。同样的,对于目标图像也是一样的考虑。因此引入的Identity Loss可以比较完美得解决这个问题。
我们构造两个噪音编码器来生成不同的噪声,其中有来分别为生成器和服务,使图像映射到噪声向量中,此时有。
那么自身损失函数定义如下,即使用L1范式来计算损失:
Bounded Focus mask
同时,图像转换任务中有些信息是我们希望完全不变的(如背景)。该方法采用注意力机制(Attention Mechanism),令生成器同时生成注意力遮罩,区分前景和背景(0表示背景,1表示前景)。
但现有的方法往往不限制遮罩的形态,因此本文作者提出边界注意掩模(Bounded Focus Mask),对注意力遮罩增加两种限制:
- 每一个像素趋向于0/1,即明显划分前景和背景;
- 前景的面积根据不同任务限制在特定范围。
边界注意掩模可以帮助生成器集中精力在需要修改的区域,从而提高生成效果。
例如眼镜摘除任务,我们并不希望在摘除的过程中模型还把背景色给改了,因此,可以先将人像给摘出来,也就是把前景和后景区分开来,再进行对人像的处理。
假设此时表示边界注意掩模,那么可以计算该损失如下:
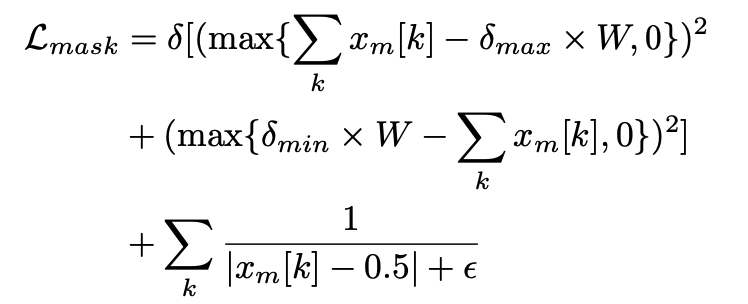
由于并没有说明边界注意掩模是如何得到的,个人对这方面知识还比较欠缺,所以就留下此处日后填坑~
(蹲位占坑)
实验结果
⚠️ 以下部分作者在知乎的描述足够清晰,因此直接拿过来摘录了。
为说明每一部分loss的有效性,该工作进行了消融实验,结果如下(量化测试见原论文):

图5. 消融实验结果。其中ACL-GAN是有所有loss的模型;ACL-A是去掉ACL loss;ACL-I是去掉identity loss;ACL-M是去掉mask loss。
虽然每一种模型都成功实现了性别转换,而且结果已经可以以假乱真,但仔细比较,我们仍然可以发现不同约束的作用,增强了该方法的可解释性。该实验结果符合分析:ACL-A的结果虽然成功转换,但生成图片和原图之间关联性不强,如发色、肤色、周围、牙齿等发生明显变化;ACL-I的结果视觉上差距不大,但量化指标略低于ACL-GAN;ACL-M的背景明显发生变化,图片质量也略低于ACL-GAN,原因是mask可以帮助生成器将注意力集中在前景上。
为了验证该方法在不同任务上的表现,作者在眼镜去除、性别转换和自拍到动漫转换三个任务上,与多个现有方法进行了比较,这三个方法对生成器的要求侧重各不相同,通过结果很明显可以看出来生成器完美胜任了这三个任务,而且规避了cycle loss的缺点。

图6. 眼镜去除任务比较
眼镜去除任务主要有两大难点:1)眼镜外的区域要求完全保留不变;2)眼镜隐藏的部分信息要合理的补充出来,如太阳镜完全遮住眼睛。可以看到,ACL-GAN不仅成功完成上述任务,而且没有留下任何“作弊”的痕迹。

图7. 性别转换任务比较
性别转换任务具有公认的三大难点:1)多模态变化,对于同一张输入,可以有多种输出对应;2)性别转换不仅要求改变颜色和纹理,还需要改变形状(如头发);3)配对的数据无法获得。即使面对这些难点,ACL-GAN仍然很好的完成了该任务,无论是头发、胡须的变化,还是五官特征、背景的保留,都优于现有方法。

图8. 自拍到动漫转换任务比较
自拍到动漫转换任务改变幅度最大,整张图片风格和主题都需要发生较大改变。ACL-GAN生成的结果自然,而且符合动漫人物的特征(如大眼睛、小嘴巴等) ,而且也与原图有更大的相关性。
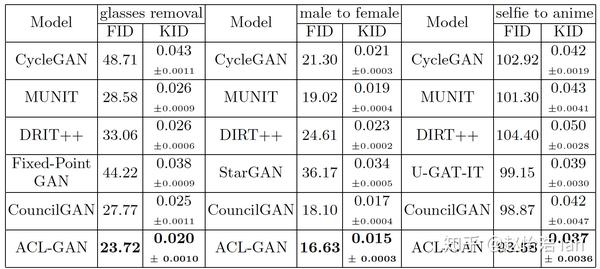
图9. 多种方法在不同任务上量化比较
为了进一步证明该方法的有效性,作者采用FID、KID指标量化评价三个任务上不同方法的表现,ACL-GAN都取得了最优的成绩,大部分结果都远远优于采用cycle loss的方法。

除此以外,该方法的网络参数较小,与大部分已有方法相当。ACL-GAN的参数数量甚至不到表现相近方法(CouncilGAN、U-GAT-IT)的一半。具有较小的训练和存储开销。










