
【图像处理】Haar特征描述算子
Haar特征描述算子
经过前面的学习,个人对几个基础概念仍然有些模糊,比如说图像特征、级联分类器等,所以这篇笔记就结合这些天查阅到的知识点和Datawhale提供的学习内容一起记录一下,会比较注重概念的理解,文字内容多一些~
图像特征
实际上,计算机是不认识图像的,但倘若我们能够将图像数字化地输入计算机,它就能够理解不同的图像,从而有真正意义上的视觉。所以在进行人脸检测或者识别的过程中,需要关注的是如何从图像中提取出有用的数据或信息,得到图像的“非图像”的表示或描述,比如常用的数值、向量等。这个过程就是特征提取。而提取出来的特征我们可以通过训练过程教会计算机如何懂得这些特征,从而使得计算机具备识别图像的能力。
基础概念
特征
严格上说,特征是某一类对象区别于其他类对象的相应特点或特性。对于一幅图像而言,它自身的纹理、亮度等等,都可以成为区别于其他图像的自身特征。当然有些特征需要经过变换处理之后才能得到,需要我们转换成直方图等等。
特征向量
如果现在我们想要表示一个抽象的对象,可以把这个对象的特征们都组合在一起,形成一个特征向量来表示。如果这个物体只有单个特征,那特征向量就是一个一维的向量。如果有n个特征,那对应的,特征向量将是一个n维的。
如下图所示,左图是一些在三维空间中的样本点。假设这些样本是鸢尾花,那么三个坐标轴可能分别代表花瓣的“长度”、“宽度”、“厚度”三个特征,给出三者的分数后,便可在三维空间中详细表示。例如,现在使用一个三维的特征来代表一个植物对象,比如(5, 6.7, 1)。
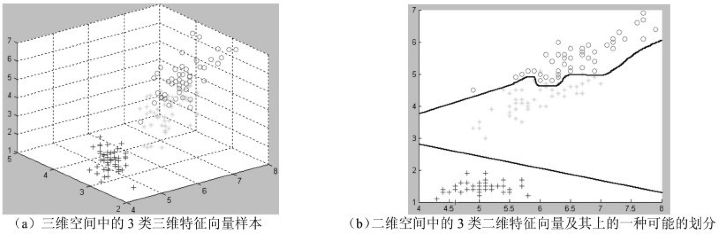
特征提取原则
其实图像识别是一个分类的过程。我们需要识别出某图像所属的类别,就需要将它和其他不同的图像区分开来。那么这就要求选取的特征不仅要能够很好地描述图像,重要的是还要能够很好地区分不同类别的图像。
我们更希望选择那些在同类图像之间差异较小,但是在不同类别的图像之间差异较大的图像特征作为我们的判断标准,可以称它们为是最有区分能力的特征。
那么重点来了,在特征提取的过程中我们应该注意些什么呢?
如果在分类过程中,仅仅是简单地提取图像中所有像素的灰度值作为特征,虽然可以尽可能地提供信息给分类器,但是高纬度意味着高计算复杂度,在后续的处理和识别中很容易导致维度灾难。
所以,我们仅仅只需要将部分像素信息交给分类器就已经足够了。
比如说,在表情识别的时候,我们并不需要肤色、面部轮廓等特征,只要给出眉毛、眼睛、和嘴这些表情区域作为特征提取的候选区,就已经完全足够了。
评价标准
评价标准其实有一定的主观性,但是还是有一些原则是可以普遍遵循的,比如说下面这几点:
- 特征应该容易提取,也就是说在提取的过程中不应该花费过多的代价。
- 选取的特征应该对噪声、不相关的转换等操作不敏感。
- 寻找一个最具区分能力的特征。
直方图及其统计特征
其实直方图更多是作为一种辅助图像分析的工具,但它也可以作为图像纹理描述的一种强大手段。
笔者在上一篇博客已经详细阐述了图像纹理的概念及其特点,它具有一定的周期性。我们知道,纹理区域的像素灰度级分布具有一定的形式,而直方图又恰好可以用来描述图像中像素灰度级分布的有力工具,所以我们当然可以使用直方图来描述图像纹理咯~
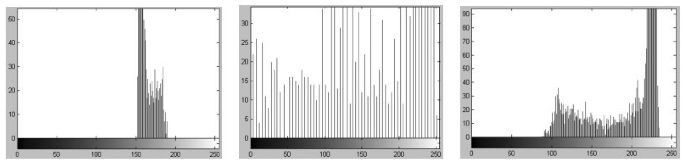
那么,毫无疑问的是,相似的纹理具有相似的直方图,也就可以说明,直方图和纹理之间存在一定的对应关系。然后,经过分析可以想象到,直方图本身就是一个向量,而向量的维数是直方图统计的灰度级数,因此我们可以直接把这个直方图形成的向量作为代表图像纹理的样本特征向量,交给分类器处理,就像LBP直方图所做的工作那样。
当然,还有其他思路,比如说从直方图中提取出能够描述自身的统计特征,然后组合成样本的特征向量,这样还可以降低特征向量的维数。
级联分类器
在上节的学习过程中,遇到了一个新的名词,叫做级联分类器。我不仅不知道它是个什么东西,还老念错它的名字,所以也找了一些资料,决定搞明白它到底是个啥玩意。
概念理解
通常情况下,分类器需要对多个图像特征进行识别。比如在识别一个动物是狗还是其他动物的时候,可能需要根据多个条件进行判断,如果首先就比较它们有几条腿:
● 有“四条腿”的动物被判断为“可能为狗”,并对此范围内的对象继续进行分析和判断。
● 没有“四条腿”的动物直接被否决,即不可能为狗。
这样,仅仅比较腿的数目,根据这个特征就能排除样本集中大量的负类(例如鸡、鸭、鹅等不是狗的其他动物实例)。
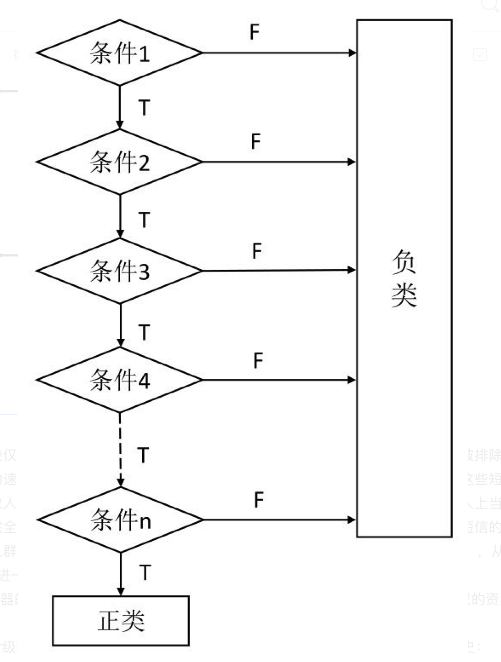
级联分类器就是基于这种思路,将多个简单的分类器按照一定的顺序级联而成的。
它将多个弱分类器串联成了强分类器,其中弱分类器是一些性能受限的分类器,它们无法正确区分所有事物。而强分类器是可以正确地对数据进行分类的。之所以以弱分类器为基础,是因为这种技术可以避免执行高精度的单一分类器所产生的问题。
如果一味强调分类器的精确度,可能会变成计算密集型且运行速度变慢。
级联分类器的基础示意图如下图所示:
优势
在开始阶段仅仅进行非常简单的判断,就能够排除明显不符合要求的样本。那些在开始阶段就被排除的负类,之后都不需要参与分类,只有正样本才会送到下一个强分类器进行再次检验,这样就保证了最后输出的正样本的伪正(false positive)的可能性非常低。这样很大程度提高了后面分类的速度,而且每个弱分类器也不需要太精确。
Haar特征及其级联分类器
Haar特征可以用来反映图像灰度变化,而使用该算子进行人脸识别时,正是从人脸灰度变化角度考虑的。
概念与应用
研究者发现,从像素的差值这个角度考虑,两幅看似不相关的图像可能会存在一定的相关性。随后提出的Haar特征正是从这个角度出发,这些特征包含了垂直特征、水平特征和对角特征。根据特征的特点,构建了特征模版,使用某类模版可以判断是否具备某类特征。
Haar算子如今普遍适用于行人检测和人脸检测中。
Haar特征的计算
简单的几个Haar特征如下图所示,它主要反映的是图像的灰度变化(你品,你细品),它将像素划分为模块后求差值。其中特征模版是用黑白两种矩形框组合成特征模版的。
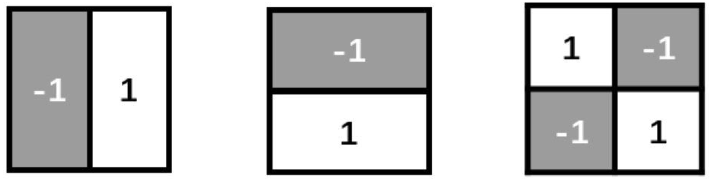
在特征模版中,用白色矩形像素块的像素和减去黑色矩形像素块的像素和来表示该模版的特征。那么经过上述处理之后,人脸部的一些特征就可以使用矩形框的差值来简单表示,其中公式如下:
之所以可以使用haar算子来识别某些面部特征,是因为在我们的面部构造上存在了一些明显的特点。
比如说眼睛的颜色比脸颊的颜色要深,那么让这两者的区域像素和做减法操作时,其差值就会比较大。但假如我们对两个都是脸颊的区域做这样的操作,显然差值很小,有可能是0。那么这样眼睛区域和非眼睛区域就能够使用差值的大小来进行区分了。
因此,经过分析发现,面部的这些特点使得有很多区域都可以借助不同的模版来计算并区分。

同样的,我们希望当把矩形放到人脸区域计算出来的特征值和放到非人脸区域计算出来的特征值差别越大越好,这样我们就能够用来区分人脸和非人脸了。
关于Harr特征中的矩形框,有如下3个变量。
● 矩形位置:矩形框要逐像素地划过(遍历)整个图像获取每个位置的差值。
● 矩形大小:矩形的大小可以根据需要做任意调整。
● 矩形类型:包含垂直、水平、对角等不同类型。
上述3个变量保证了能够细致全面地获取图像的特征信息。
积分图
前面说到,计算haar特征之前,要先计算两块区域的和,再算它们之间的差。
都说程序员是最知道偷懒的,他们发现光是计算区域和也好累,因为如果我们细致全面地获取图像的特征信息,使用不同的矩形进行特征提取,若同一个像素包含在不同的重叠矩形区域中会被多次遍历,导致计算量加大。
所以学者们又提出了简化Haar特征的方法,也就引出了积分图的计算。假设现在有一张图,如下图所示:
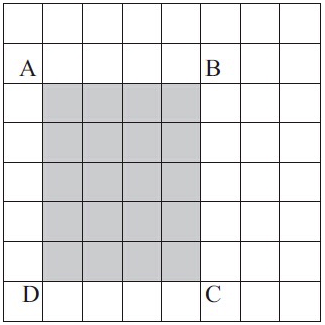
如果需要计算图像中任意矩形区域的大小,不需要遍历区域内的所有像素。
想象下图中左上的点和任何相对的点P形成的矩形。设AP表示这个矩形的面积。如前图所示,AB表示通过取左上角点和相对的B点形成的5×2矩形的面积。为了清楚起见,看一下下图:
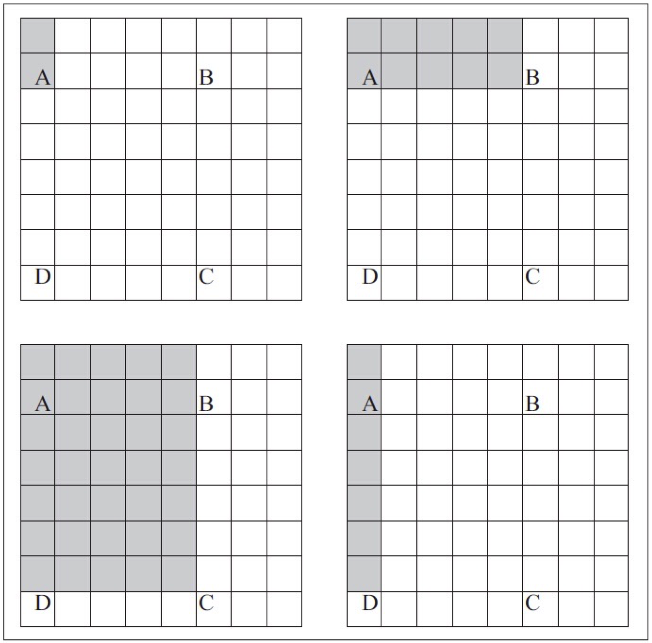
上图中的左上部分,着色像素表示左上角与点A之间的区域。这个区域用AA表示,剩下的图用AB、AC、AD表示。若想计算上图ABCD区域,将使用下列公式:
这种特定的公式有什么特别的地方吗?
⚠️ 实际上我们知道,提取图像的Haar特征需要计算多个尺度矩形的和。而这些计算是重复的,因为反复遍历了同一个像素。那么上面这种方法借助了动态规划的思想,避免了对同一个位置的重复计算,极大地节省了时间开销。
Haar级联分类器
这下总算能具体说说Haar级联分类器到底是什么,应该怎么使用的了!!其实这部分的内容,助教给的学习资料已经很清楚了,甚至很多图像处理的书都没他讲的明白。。
简单地说,在进行人脸检测的过程中,需要使用一个强分类器,且其由多个弱分类器组成。那么其中的每个弱分类器都只包含一个Haar特征。每个分类器都将确定一个阈值,如果某区域的处理差值小于该阈值,则被归为负类,反之则进行下一级的弱分类,最终经过多个弱分类器后,可完成检测。其分类过程如下图所示:
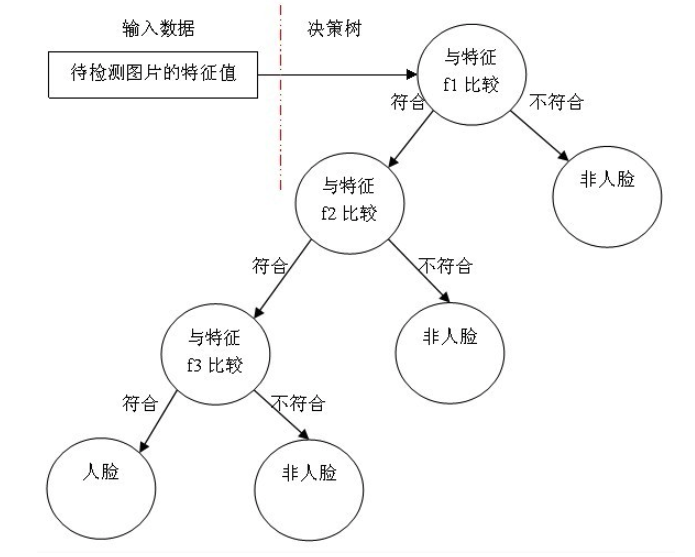
那么接下来,再具体地说明执行过程:
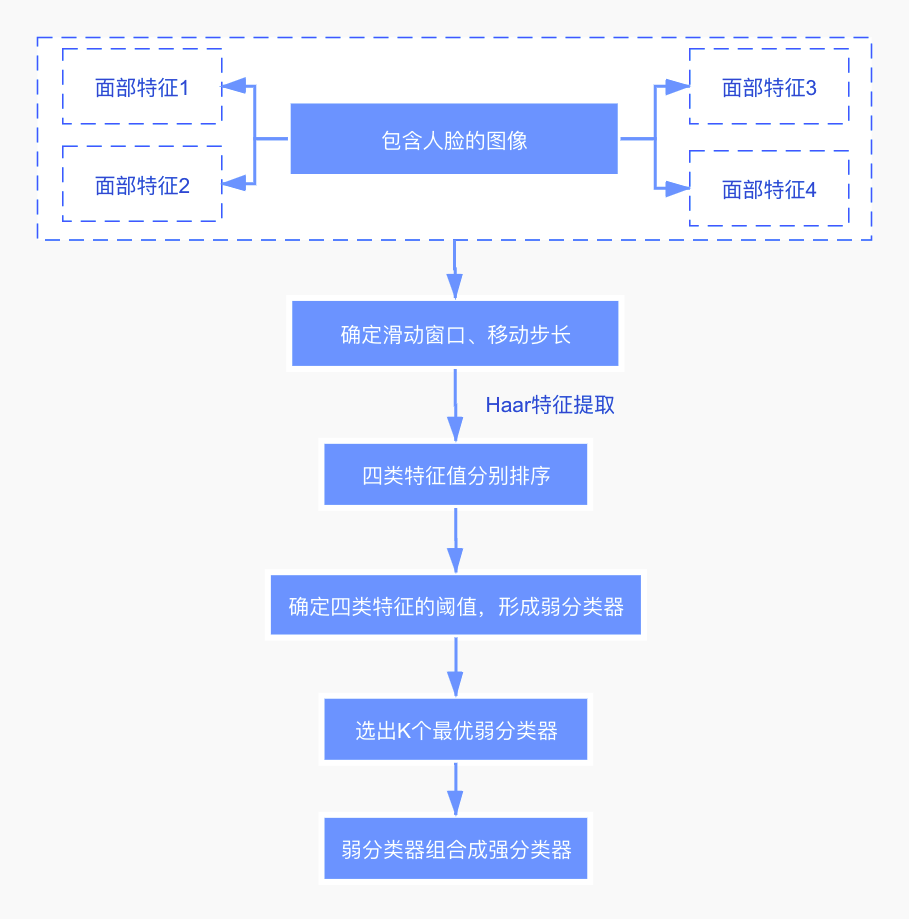
- 首先,对于一幅图像,它可能存在K个面部特征,假设这些面部特征可以用来区分眼睛、眉毛、鼻子、嘴等特征。
- 确定一些超参数,如滑动窗口的大小,及窗口的移动步长。窗口从上往下,从左向右地滑动。在滑动的过程中,每次都可以计算出一个数值。
- 滑动结束时,将得到的特征值进行排序,并选取一个最佳特征值(最优阈值),使得在该特征值下,对于该特征而言,样本的加权错误率最低。这样就训练出了一个弱分类器。
- 因为面部特征的不同,我们将采用不同的滑动窗口进行特征提取。所以根据不同的窗口识别不同的特征,进而训练出了不同的弱分类器。
- 对于每个弱分类器都将计算它的错误率,选择错误率最低的K个弱分类器,组合成强分类器。
- 一组样本投入强分类器后,在每个渐进的阶段,分类器逐渐在较少的图像窗口上使用更多的特征(负类被丢弃)。如果某个矩形区域在所有弱分类器中都被归结为正类,那么可以认为该区域是存在人脸的。
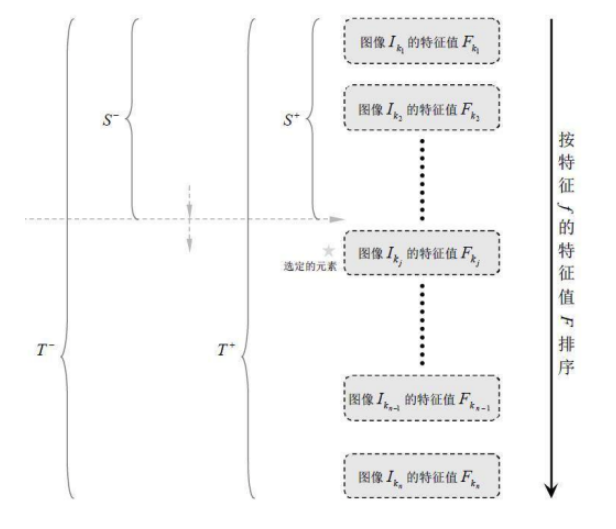
其中,弱分类器训练的具体步骤如下:
1、对于每个特征 𝑓,计算所有训练样本的特征值,并将其排序:
2、扫描一遍排好序的特征值,对排好序的表中的每个元素,计算下面四个值:
计算全部正例的权重和𝑇+;
计算全部负例的权重和𝑇−;
计算该元素前之前的正例的权重和𝑆+;
计算该元素前之前的负例的权重和𝑆−;
3、选取当前元素的特征值和它前面的一个特征值之间的数作为阈值,所得到的弱分类器就在当前元素处把样本分开 —— 也就是说这个阈值对应的弱分类器将当前元素前的所有元素分为人脸(或非人脸),而把当前元素后(含)的所有元素分为非人脸(或人脸)。该阈值的分类误差为:
于是,通过把这个排序表从头到尾扫描一遍就可以为弱分类器选择使分类误差最小的阈值(最优阈值),也就是选取了一个最佳弱分类器。
级联分类器的使用
在OpenCV中,有一些训练好的级联分类器供用户使用。这些分类器可以用来检测人脸、脸部特征(眼睛、鼻子)、人类和其他物体。这些级联分类器以XML文件的形式存放在OpenCV源文件的data目录下,加载不同级联分类器的XML文件就可以实现对不同对象的检测。
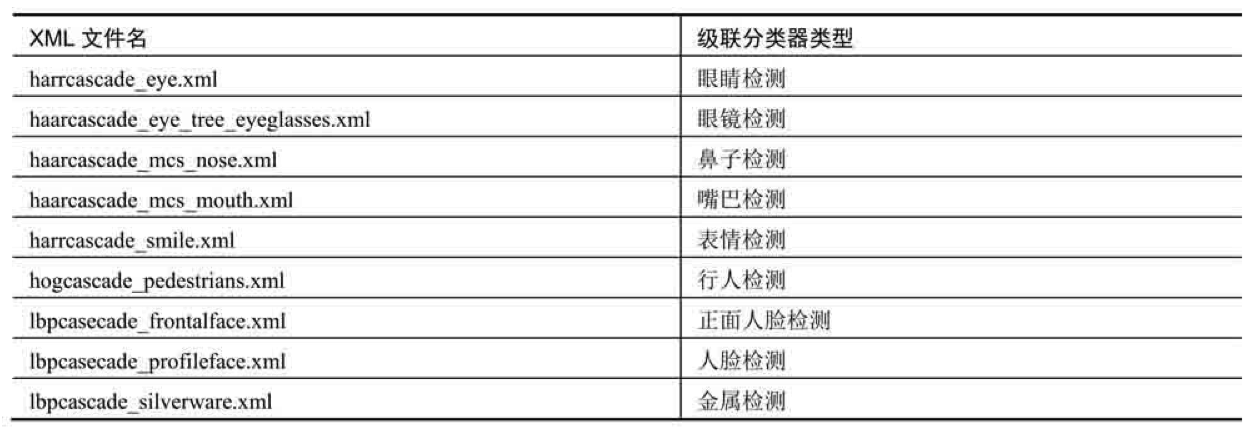
OpenCV自带的级联分类器存储在OpenCV根文件夹的data文件夹下。该文件夹包含三个子文件夹:haarcascades、hogcascades、lbpcascades,里面分别存储的是Harr级联分类器、HOG级联分类器、LBP级联分类器。
其中,Harr级联分类器多达20多种(随着版本更新还会继续增加),提供了对多种对象的检测功能。部分级联分类器如下表所示:
openCV实现过程
静态检测
第一步仍然是导入环境包,图片读取,灰度转换。
1 | filepath = '../img/cv_2.jpeg' |
随后加载haar的级联分类器,并且使用detectMultiScale()函数来处理灰度图,并用矩形框将人脸框出。
1 | faceCascade = cv.CascadeClassifier(cascadepath) |
得到最终的检测结果如下图所示,效果比LBP好一些似乎,因为上次也是这张图,结果就是检测不全。

单独使用了一下眼睛检测,一定是我牙不够白…

动态检测
接下来就是使用摄像头进行动态检测的过程了。DynamicDetect函数主要包括:打开摄像头、读取帧、检测人脸、扫描检测到的人脸中的眼睛,并使用不同颜色绘制出矩形框。这次助教写的函数解释很清楚,贴出来记录一下重点:
detectMultiScale有许多可选参数;眼睛是一个比较小的人脸特征,并且胡子或者鼻子的本身阴影以及帧的随机阴影都会产生假阳性。通过限制对眼睛搜索的最小尺寸为40x40像素,可以去掉假阳性。
1 | detectMultiScale(image, scaleFactor, minNeighbors, flags, minSize, maxSize) |
- scaleFactor:为每一个图像尺度中的尺度参数,默认值为1.1。scaleFactor参数可以决定两个不同大小的窗口扫描之间有多大的跳跃,这个参数设置的大,则意味着计算会变快,但如果窗口错过了某个大小的人脸,则可能丢失物体。
- minNeighbors:参数为每一个级联矩形应该保留的邻近个数,默认为3。minNeighbors控制着误检测,默认值为3表明至少有3次重叠检测,我们才认为人脸确实存。
个人的实现过程如下,基本上和助教给的差不多:
1 | PathOfFaceCascade = '/Users/sonata/opt/anaconda3/share/opencv4/haarcascades/haarcascade_frontalface_default.xml' |
非极大值抑制(NMS)
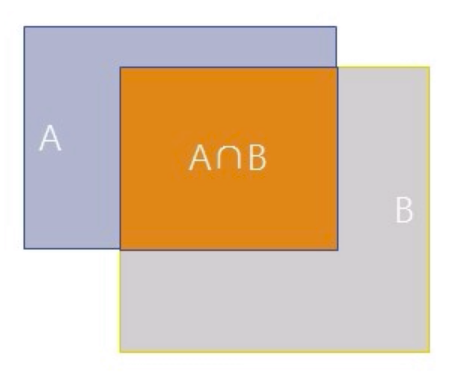
不知道各位小伙伴有没有想到,一张脸可能会被不同形状的候选矩形框检测出,那么最后将决定以哪个框为我们的最终结果呢?这就需要使用到NMS(Non-Maximum Suppression)方法来去除多余的框。

公式理解
- 首先对所有检测出来的框,根据分数从高到低进行排序。
- 从分数最高的框开始,计算与分数比自身地的框的IOU,如果IOU大于一定的阈值,就把分数较低的那个去掉。
- 便利剩余未被去掉的框,重复步骤2的操作。
- 最后得到一组得分较高且不重复的框。
总结
- 分类任务中可借助图像特征和直方图来完成。
- 级联分类器有强弱之分,多个弱分类器组成了强分类器。Haar特征就是一种弱分类器。
- Haar特征值等于白色矩形像素块的像素和减去黑色矩形像素块的像素和。
- 人脸包含的每个特征都可以训练出一个弱分类器,选择出K个最优分类器进行组合成为强分类器。










