
【数据分析】数据重构与可视化
数据重构使用函数
使用pd.merge实现数据合并
1 | pandas.merge(left, right, |
-
left : DataFrame
-
right : DataFrame or named Series
-
how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’(设置数据连接的集合操作规则)
- left: 返回的结果只包含左列
- right: 返回的结果只包含右列
- inner: 交集
- outer: 并集
-
on :label or list(此参数只有在两个DataFrame有共同列名的时候才可以使用)
-
left_on与right_on: label or list, or array-like(合并两个列名不同的数据集)
-
left_index与right_index : bool, default False(合并索引)
-
suffixes : tuple of (str, str), default (’_x’, ‘_y’)(为重复列名自定义后缀)
stack()函数
pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”
常见的数据的层次化结构有两种,一种是表格,一种是“花括号”,即下面这样的l两种形式:
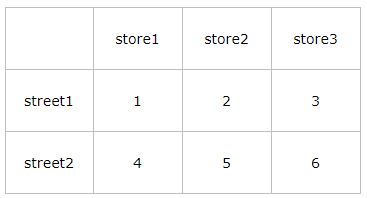
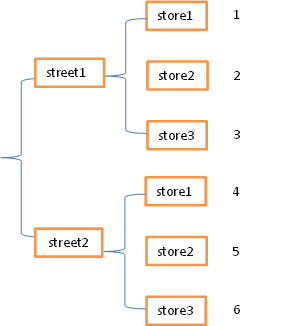
stack函数会将数据从”表格结构“变成”花括号结构“,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构“变成”表格结构“,即要将其中一层的列索引变成行索引。


All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.







